Part I: Simplifying Transformer Research with xFormers & Lightning

Recently we’ve seen a large growth in variations of the Transformer model (Efficient Transformers: A Survey). However, leveraging improved variations requires custom complicated implementations hidden in a variety of dense libraries. As a result we still see unoptimized Transformers in the wild, with simple attention or sparse attention blocks, lacking fused transformer operations leading to longer training times and increasing costs for training.
xFormers provides a simple composable solution to building Transformers, abstracting out optimized GPU kernels (that are enabled automatically for you), fused Transformer layers which go beyond what PyTorch can offer whilst remaining seamless for the user (just a torch.nn.Module). Paired with Lightning, this creates an extremely powerful tool to train models with high levels of flexibility.
Below we go through an example of implementing a Vision Transformer using xFormers and Lightning, and a few tips to scale your model on multiple GPUs with minimal code changes. Focus on the research, not the boilerplate!
What is xFormers?

xFormers boils down to a modular library of transformer components, additionally providing config factories to flexibly instantiating the transformer model. The abstractions within xFormers also allow you to easily implement your own modules.
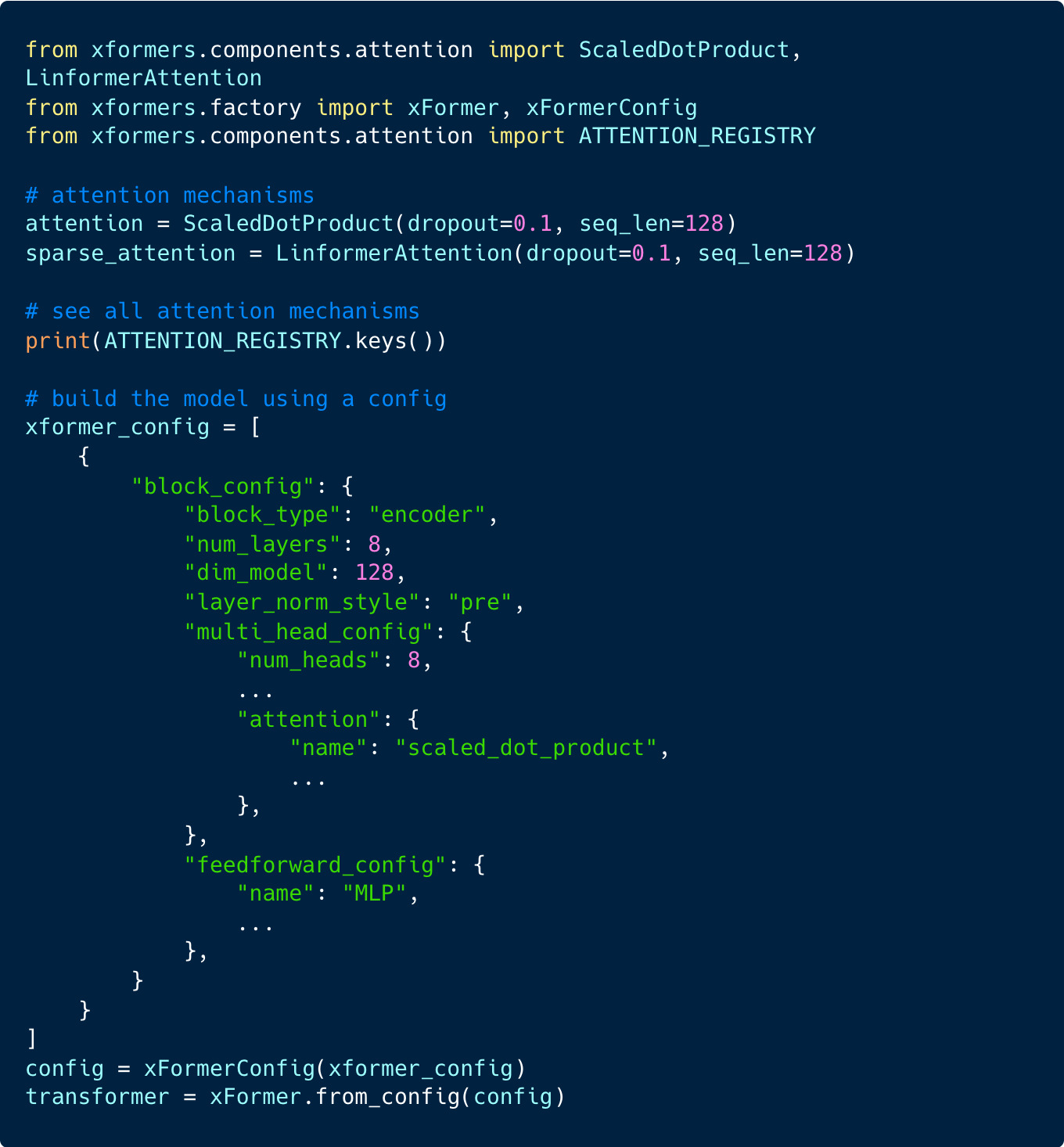
Rapid Prototyping with xFormers and Lightning
Below is a snippet of the Vision Transformer Lightning Module, adapted from this awesome repo to include xFormers. Using xFormer configs allows you to swap out attention blocks and other pieces of the Transformer model seamlessly.
We define the config as a simple dictionary (we only define the encoder here) and pass arguments controlling everything from the type of attention to the dropout or layer norm style. This makes it easy to configure the transformer from the LightningModules’ constructor.

For example, to swap to another attention mechanism all we need to do is pass attention="linformer" to the VisionTransformer constructor.

Paired with the lightning-bolts CIFAR module we’re able to train this model very easily! We define the DataModule + the transforms of the data we’d like to use. We then instantiate our VisionTransformer and create our Lightning Trainer. Finally, we call fit, and Lightning handles the rest!
If you use install Triton and are running on an Ampere GPU, xFormers will automatically enable very efficient CUDA kernels to speed up training for free, as well as automatically enable fused layers for typical Transformer operations.
First we define our imports:

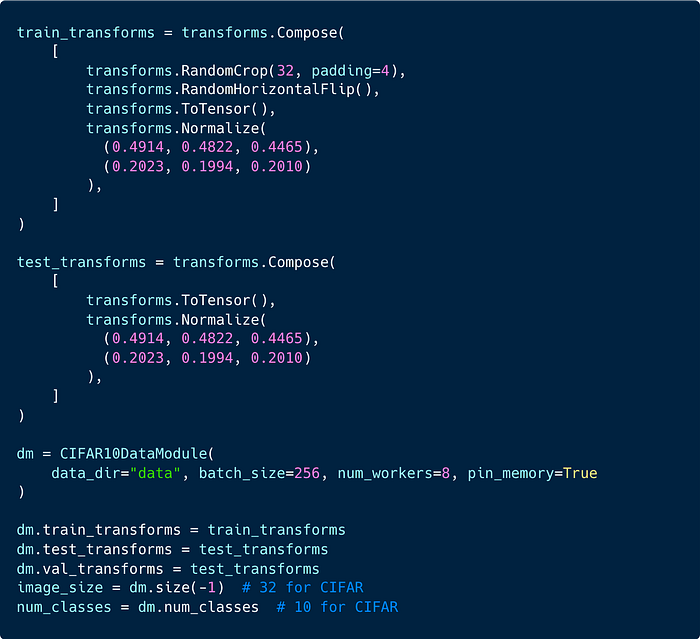
We then define our data transforms and data module:
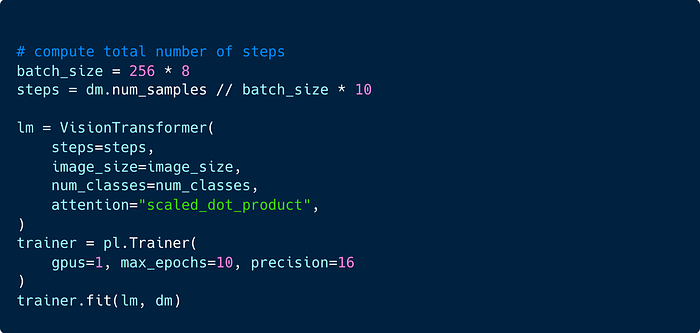
Finally we define our VisionTransformer and train using the Lightning trainer!
To give a sense of how important the ability to swap blocks out when experimenting is, below are reported throughput times in xFormers with different attention blocks at various sequence lengths. This is extremely critical for tasks such as text summarization across large spans of tokens, ultimately reducing cost.
Leverage DeepSpeed for Scaling Transformers
Enabling DeepSpeed will provide distributed optimizations for memory, allowing you to scale your model to larger sizes. For PyTorch Lightning, all this requires is an argument passed to the Lightning Trainer!
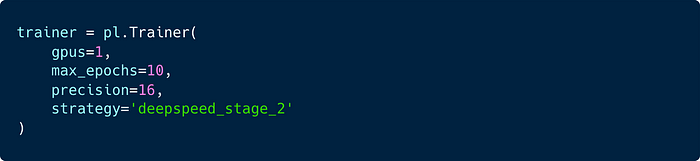
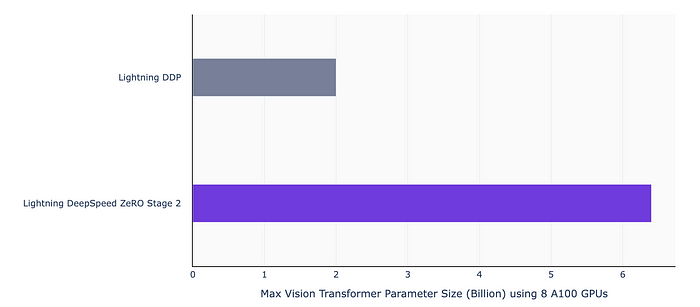
We choose DeepSpeed ZeRO Stage 2 when training primarily because it’s a good tradeoff between speed and memory optimization. With ZeRO Stage 3 we achieve larger model sizes, however observe degradation in training time and even more so if we enable offloading. When training from scratch at scale this can become a bottleneck and scaling the number of GPUs is usually a better factor to control. See the extensive model parallelism docs for more information!
A tip when using DeepSpeed Stage 3 is to use the configure_sharded_model hook in the LightningModule to define your modules. Under the hood this saves substantial initialization time by partitioning your model across GPUs per module.
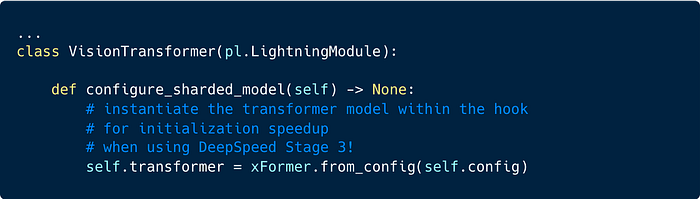
Future work within PyTorch will remove the need for such a hook in the future (see meta device for more info).
Next Steps
We hope xFormers and Lightning will usher efficient Transformer models to be the standard as model sizes continue increasing into the Trillions, whilst providing researchers the tools for creativity, experimenting with their own transformer components.
See all the available modules and in-depth examples in the xFormers documentation. Take a look at the microGPT example to see how xFormers and Lightning can be used in NLP. If interested in distributed optimizations when scaling onto multiple GPUs, check out the Lightning Model Parallel documentation!
Thanks to Benjamin Lefaudeux and the rest of the xFormers team! Huge thanks Phoeby Naren for the illustration :)

