Introducing PyTorch Lightning Sharded: Train SOTA Models, With Half The Memory
Lightning 1.1 reveals Sharded Training — train deep learning models on multiple GPUs saving over 50% on memory, with no performance loss or code change required!

In a recent collaboration with Facebook AI’s FairScale team and PyTorch Lightning, we’re bringing you 50% memory reduction across all your models. Our goal at PyTorch Lightning is to make recent advancements in the field accessible to all researchers, especially when it comes to performance optimizations. Together with the FairScale team, we’re excited to introduce our beta for Sharded Training with PyTorch Lightning 1.1.
Training large neural network models can be computationally expensive and memory hungry. There have been many advancements to reduce this computational expense, however most of them are inaccessible to researchers, require significant engineering effort or are tied to specific architectures requiring large amounts of compute.
In this article we show how easy it is to see large memory reductions using multiple GPUs by simply adding a single flag to your Lightning trainer, with no performance loss. Continue reading to see how we pre-trained a Transformer LM with NeMo showing a 55% memory improvement, and further memory reductions training other PyTorch Lightning powered models. In addition to results in NLP using NeMo Transformer LM, we show results in Speech Recognition using DeepSpeech 2, and in Computer vision training SwAV ResNet and iGPT.
Larger Model, Better Accuracy
Recent advancements in language modelling are trending towards larger pre-trained models performing better on downstream tasks. This is famously shown with the release of GPT-3 by OpenAI, their largest model at 175 billion parameters, requiring massive amounts of compute and optimization tricks to train.
When training large models, memory quickly becomes a valuable resource. As we scale our model sizes, we start to run out of memory on GPUs which limits the size of the models we can train. This can be frustrating, and leads us to try smarter memory management techniques.
Sharded Training Powered by Lightning
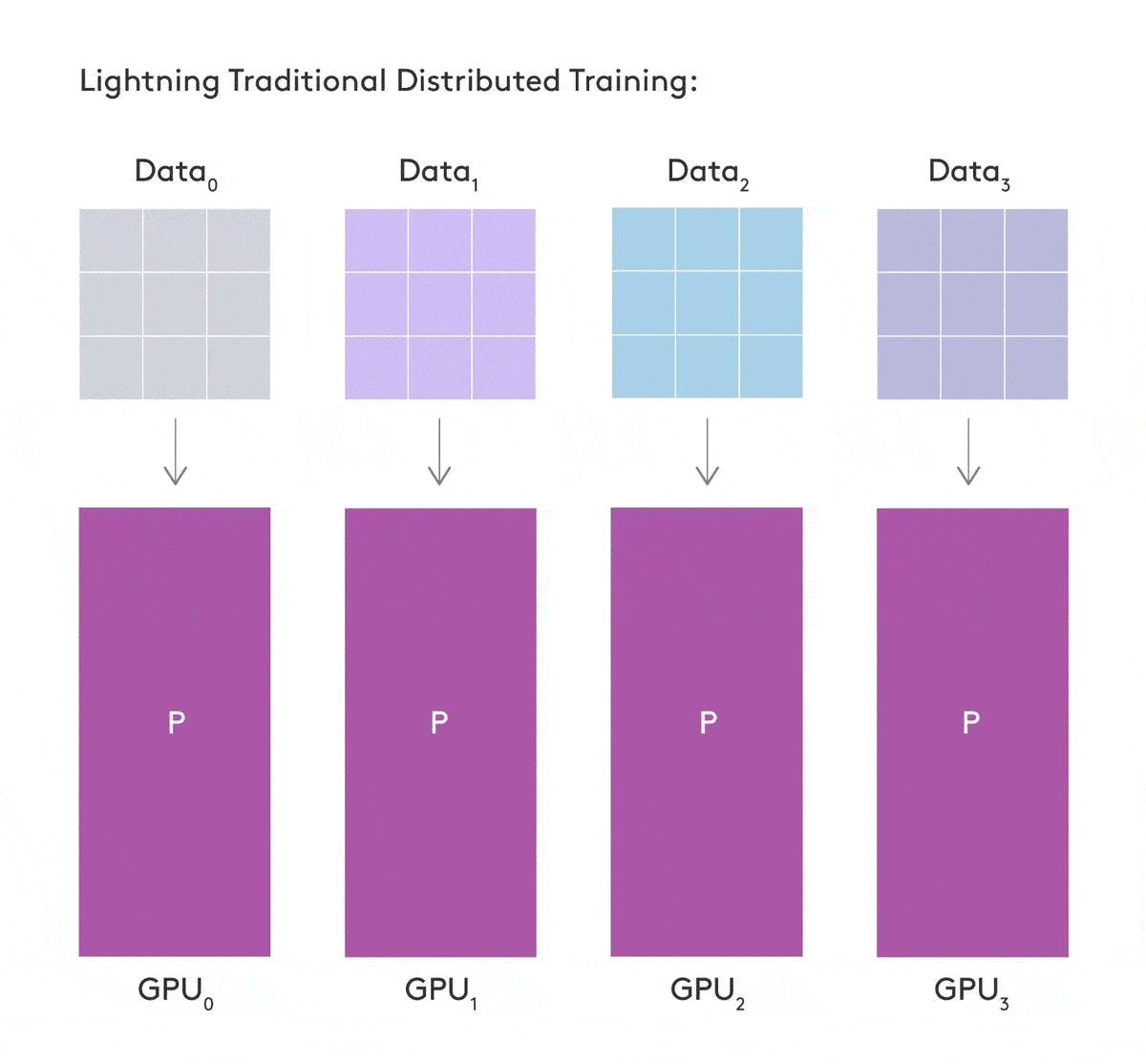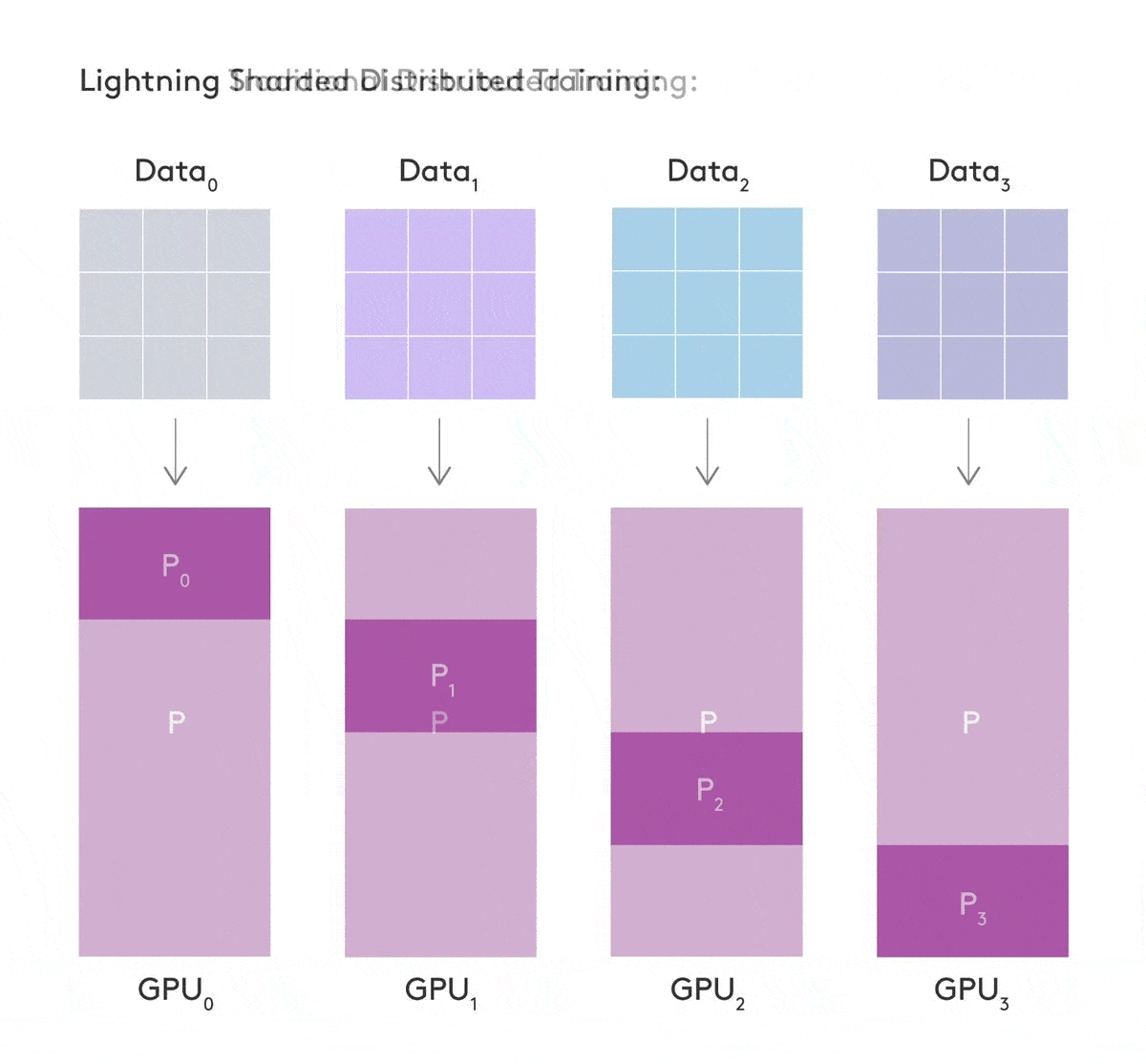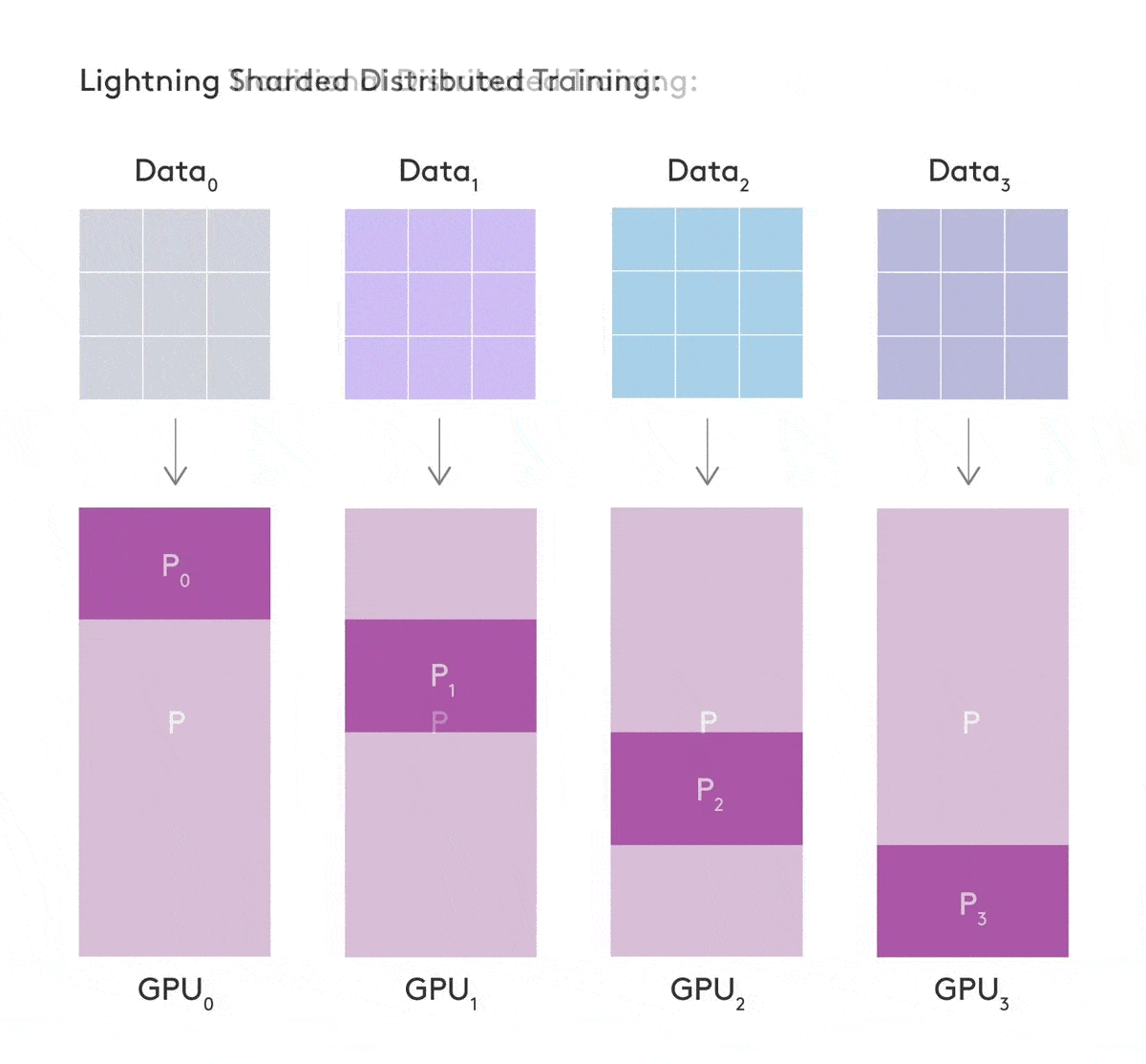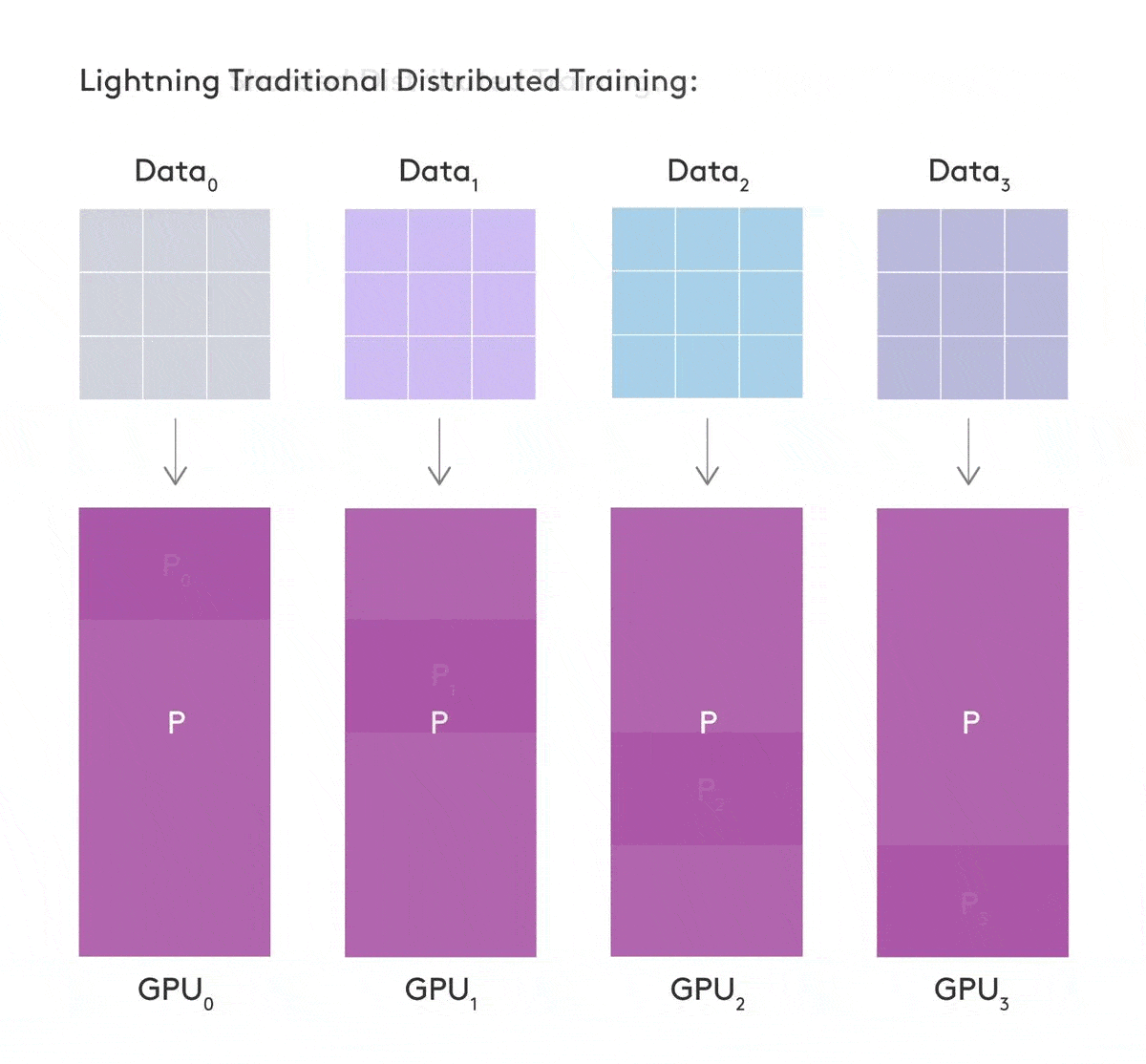
Sharded Training, inspired by Microsoft’s Zero Redundancy Optimizer (ZeRO) offers a solution to reduce memory requirements for training large models on multiple GPUs, by being smart with how we “shard” our model across GPUs in the training procedure. Sharding involves fragmenting parameters onto different devices, reducing the memory required per device. In particular, optimizer state and gradients can be sharded independent of the model, and can offer memory reductions for all architectures.

Sharded Training was built from the ground up in FairScale to be PyTorch compatible and optimized. FairScale is a PyTorch extension library for high performance and large scale training, model- and data-parallelism. In addition to Sharding techniques, it features inter- and intra-layer parallelism, splitting models across multiple GPUs and hosts.
With smart gradient and optimizer state sharding across our GPUs, we can reduce memory costs roughly a combined 4x and 8x respectively, as reported by Microsoft. This benefits all models, providing lower memory usage in training across all model architectures and training procedures. The caveat is that naive implementations have resulted in dramatic speed regressions due to the increased volume of communication required between nodes, and the lack of parallelism.
We’ve worked closely with the team behind FairScale who have spent time optimizing communications, reducing this regression to near zero whilst fitting nicely into PyTorch Lightning, allowing researchers to benefit from all the optimizations we’ve already made. You can now enjoy 55% and beyond memory reductions on all lightning modules by simply passing in a single trainer flag! This means larger models can be fit onto multiple GPU cards that are limited in memory.
Enable Sharded Training with no code changes
To demonstrate how easy it is to use Sharded Training in Lightning we use NeMo, a popular library from NVIDIA to train conversational AI models backed by Lightning. We’ll be using a vanilla Transformer LM model provided in NeMo, and be using a 1.2 billion parameter model which has a high memory requirement to train. When training large language models, memory is a valuable resource to boost the model size or to improve saturation on GPUs. To train the model we’ll be using the WikiText dataset.
First we download the dataset and extract using the processing script provided by NVIDIA NeMo. Then define the model configuration using the preset configuration file found within NeMo, modifying the data inputs to point to your dataset. We also build a simple word based vocabulary for benchmarking purposes.
After setting your model parameters, all you need to do is pass the Sharded plugin flag to the trainer enabling Sharded Training. You can increase the number of GPUs and enable native mixed precision for further memory and speed benefits. Behind the scenes, we automatically handle partitioning optimizers and all communication between GPUs.
Below you can see the memory improvement per device using Lightning’s built-in Sharding vs normal GPU scaling where the per device memory allocation stays constant. We also report a host of other models from self-supervised (SwAV), speech recognition (DeepSpeech 2) and generating pre-training on pixels (iGPT) which are all powered by PyTorch Lightning. We save up to 15 GiB of memory per GPU, which allows us to increase the model capacity. For example with the same hardware, we are able to boost out model size from 1.2 to 2 billion parameters when training our Transformer LM.

With optimized communication across GPUs, we see better scaling for intra-node performance vs our standard distributed accelerator. Note that as we scale onto many nodes memory benefits start to diminish as other factors become bottlenecks. However we continue to see good throughput scaling from Sharded training.

Use Sharded training with Lightning today
In this article we described how you can use Sharded Training with PyTorch Lightning to reduce memory requirements for your research with no code changes required. We also show that a large range of models from a variety of domains can be trained with large memory savings by simply adding a single flag to your lightning trainer, with no performance loss.
We’re working hard to add additional model parallelism techniques and ensure robustness, to improve model scaling across all PyTorch Lightning research whilst collaborating with the FairScale team. You can find more information using our Sharded Plugin, as well as upcoming model parallelism tricks within the PyTorch Lightning docs here.
Thanks to Benjamin Lefaudeux and the FairScale team, Lightning research members Ananya Harsh Jha and Teddy Koker for SwAV and iGPT.
